Pokémon Recommendation Engine
Using t-SNE, I wrote a Shiny app that recommends similar Pokémon. Try it out here.
Needless to say, I was and still am a big fan of the Pokémon games. So I was very excited to see that a lot of the meta data used in Pokémon games is available on Github due to the Pokémon API project. Data on Pokémon’s names, types, moves, special abilities, strengths and weaknesses is all cleanly organized in a few dozen csv files.
And so a few lines of dplyr action later, I had imported all data relevant to me into R and organized into a neat data set with a little more than one hundred features for every Pokémon of the first six generations (721 to be exact).
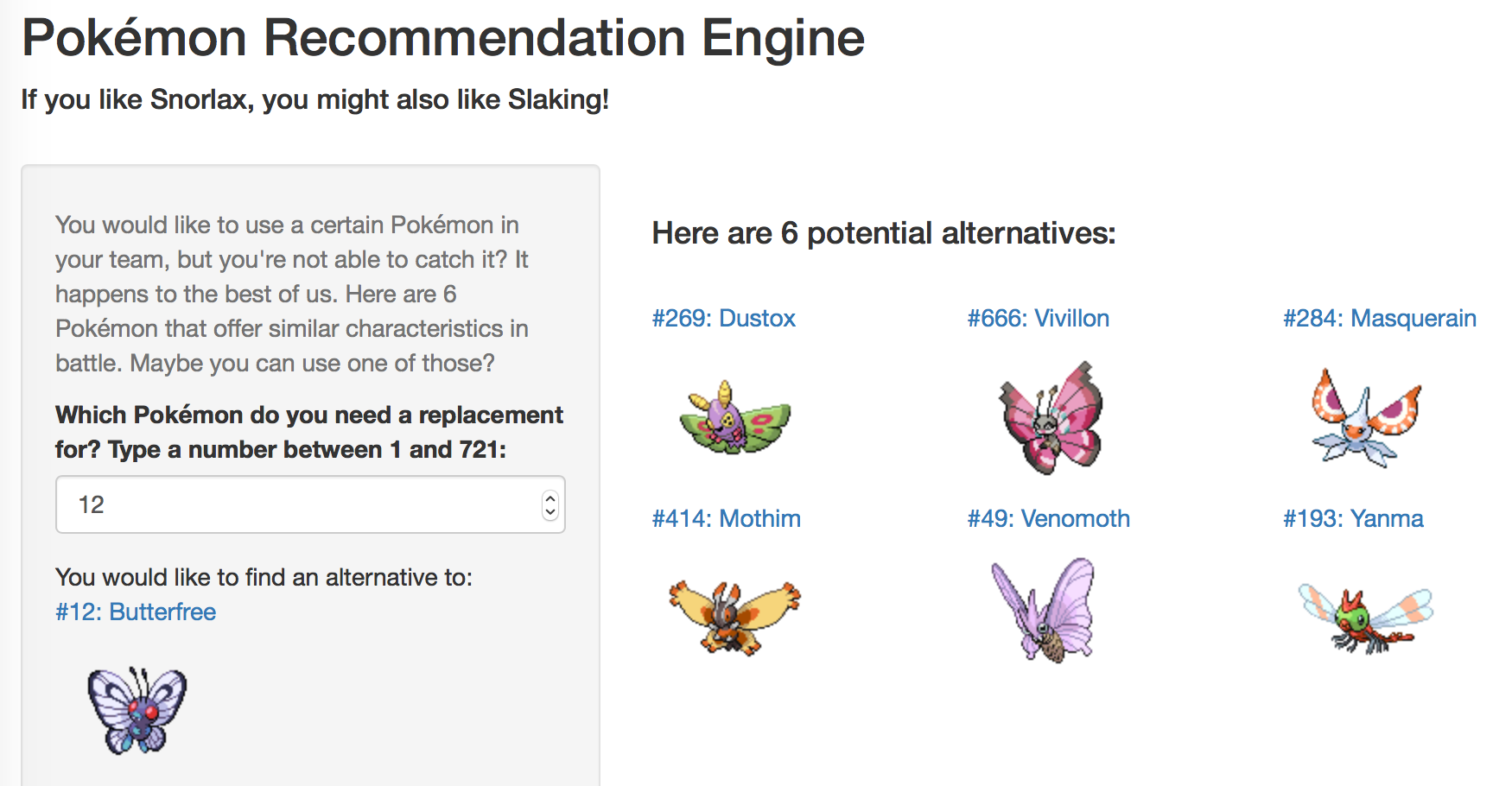
If you give a data set like this to a Pokémon nerd like me, what happens? Well, one of the big frustrations in the game can happen when for what ever reason you would like to use a specific Pokémon in your team, but you cannot catch it. Imagine that a Butterfree would be a great addition to your team because you want to have one team member with a lot of status type moves. But you’re playing the Black edition in which Butterfree cannot be caught. So what Pokémon would be good alternatives?
Here is where the Pokémon Recommendation Engine comes in. Just like Amazon recommends you similar products when you’re visiting a product page, and similar to how Spotify can recommend you music you’d might like, the Pokémon Recommendation Engine will suggest you good alternatives to a given Pokémon.
How the Recommendation Engine is Built
My goal was to get a measure of similarity between Pokémon based on which the recommendations can be made. Ideally, the recommendations would not only be based on straightforward characteristics like the evolution of the Pokémon or the type of the Pokémon; instead, it would be more interesting to get Pokémon recommended that would have similar characteristics in a Pokémon battle (sorry if I go too deep into the game here). Thus I made sure to include primarily battle related information like information on moves. Since moves have types as well, a lot of information about the Pokémon types would make its way into the data set anyway.
I then used t-distributed Stochastic Neighbor Embedding (t-SNE) to embed the data into a two-dimensional space. Now, t-SNE is meant for visualization purposes. It is not meant to calculate distances between observations. Indeed, it can take a distance matrix as input. Furthermore, one should in general not try to interpret the distance between groups of observations in the resulting t-SNE plane.
That said, I still went ahead and calculated the Euclidean distance between the Pokémon in the resulting 2D plane. I had chosen a low perplexity value for the t-SNE which led to a result in which many clusters of a few Pokémon were generated. This means that if I want to find the six nearest neighbors of a given Pokémon, chances are that those are found within one of these groups. Based on this effect, t-SNE leads to a very efficient way to get recommendations – at least for this small data set. Additionally, since the data is inherently interpretable, it was very easy to judge the result by the resulting t-SNE visualization. Indeed, for this minimum viable product, I restrained from using statistical measures. Instead, I plotted the Pokémon sprites, which are also included in the Pokémon API repository, and judged the groups through my years and years of experience as a PokeTrainer. After I played around with the perplexity value, I decided that the current solution was good enough for a first version.
And so it was time to built a small Shiny app in which one can select a Pokémon and get six recommendations. The app is online, so head over there and try for example the recommendations for Snorlax (#143).
Here is a screenshot: